
2.画像を出力する(t2i/i2i)
2_0.はじめに
1章を読んでいただけたのであれば大体の準備は整っているものと思いますが、生成AIをwebUIで使うにあたって陥りがちなポイントを説明していきます。
まずはモデルのバージョンついて。
現在の主要モデルは1.5系かXL系かになっています。特に設定をいじっていなければ導入の段階でSD1.5モデル(SD15NewVAEpruned.ckpt)がインストール済みのはずですが、宗教上の理由で1.5系を使いたくない!XL系モデルを使いたい!という方も居ると思います。
その方にも向けた説明なのですが、
1.5系は1.5系向けに作られたvae、LoRA、embedding(ネガティブTI)しか
XL系はXL系向けに作られたvae、LoRA、embedding(ネガティブTI)しか
正常に機能しません。
(vaeやLoRAやTIについては後述します)
生成された画像が変だなと感じたら、その組み合わせがズレていないか確認してください。
また、前章でも言及した通り8GB以下のグラボの場合XLモデルでの生成はかなり厳しいです。動作したとしても生成にかなりの時間を要します。
これは生成AIの特徴に起因します。基本的に1.5系のモデルはファイルサイズ2GB~4GBのものが主流、XLモデルは最低でもファイルサイズ6GB以上のものがデフォルトになっています。生成AIはグラボでモデルを読み込んでから動作するとざっくり考えてもらっていいので、8GBのグラボで6~7GBの大きさのファイルを読み込んだら後の動作に使用する余剰がほぼ無いのです。
この二点、頭の隅においておいてから次からの項目に進んでください。
1.5系とXL系の公開の間には2系モデルというものが存在しているのですが、2系は色々な理由で今でも触っている人はごく少数です。このサイトでは紹介しません。
2_1.webUIの画面を知る

画面について簡単に説明していきます。
1.現在読み込んでいるモデル。外部からモデルをダウンロードし、フォルダに入れればここでモデルを選択することができる。
モデルを入れるフォルダはStabilityMatrix-win-x64/Data/Models/StableDiffusionです。StabilityMatrix上でCivitAIからモデルをダウンロードした場合もそこに配置されます。
2.タブ。今回はtex2imgというタブで生成を行う。tex2imgはtext(文章)to(から)image(画像)を生成するという意味。t2iと俗に言われる為、以降はそちらの略称を使います。
3.プロンプトを入れるテキストボックス。出力したいものをここで表現します。生成AIの特徴として基本的には最初に書かれたものが強く表現され、後ろの単語ほど弱く表現される場合が多いです。例えば女の子を出したければ1girlです。
4.ネガティブプロンプトを入れるテキストボックス。出力したくないものをここに入力します。例えばプロンプトには1girlを入れたがスカートを履いてほしくない場合はここにskirtと入力します。
5.出力する画像の設定。
6.拡張機能群。今回は使用しません。
7.Generateボタンを押すと画像生成が始まります。
右クリックするとGenerate foever/Cancel Generate foeverという項目が出てきますが、Generate foeverを選択すると次に右クリックからCancel Generate foeverを選択するまで無限に画像が生成されます。
8.出力画像:通常絵文字の下にズラズラと英文が表示されますがこれは画像に保存されるメタデータと言い、どんな設定でどんなモデルで生成したかのメモです。これは覚えておかなくても画像そのものに情報が保存されているので、あとから「PNG Info」タブで見ることが出来ます。
絵文字について
フォルダ:通常生成画像が保存されるフォルダをエクスプローラーで開く
フロッピー:保存する
ひきだし:生成画像をまとめてzipにする。Batch(複数)処理したとき用
絵:img2imgに生成した画像を送る
パレット:img2imgのインペイントに生成した画像を送る
定規:Extrasに画像をおくる。画像を拡大したり背景を抜いたり拡張機能で絵をAIドット化したりできる
この画面は拡張機能を入れればタブが増えたり、モデル名表示の隣にvaeやclipskip,xformersの使用の有無などの項目を表示非表示させることが出来ますが、今は必要ないので別の章で説明します。
ノイズ処理のアルゴリズム。出力の際の計算方式のようなもの。基本いじらなくていいです。
初期設定のDPM++ 2M Karras、Euler a、DPM++ SDE Karrasなどが使われることが多いです。
2_2.文章から画像を生成する(t2i)
では画像を生成してみましょう。
プロンプトとネガティブプロンプトのテキストボックスに何も入力せず一度右上のGenerateボタンを押してみましょう。変な画像が生成されます。これは、AIが出力すべき目標がわからない状態で出した画像です。
次にプロンプトにflowerと入れてみてください。ネガティブ欄は空白でOK。花が出ましたか? 何回か出力してみると、絵の花が出たり、写真の花が出たり、色んな色が出力されます。
ここで、プロンプトにflowerを入れたままの状態でネガティブ欄にpinkと入力します。
すると、生成する画像の花でピンクの花が極端に出にくくなります。(出る場合もあります)
これが基本的な画像生成のやり方です。
巷で騒がれてるAIイラストというような美少女は初期インストールのSD15NewVAEpruned.ckptモデルではまず出力されません。イラスト特化に学習されてないからです。
2_3.画像を入力して、画像を出力する(i2i)
img2imgのタブに移動します。
img2imgはimg(画像)to(から)img(画像)を生成するという意味。
i2iと俗に言われる為、以降はそちらの略称を使います。
2_1の図の2番のタブ部分、tex2imgの隣りにあります。
「ここに画像をドロップ-または-クリックしてアップロード」
と書かれでいる部分に参照したい画像を入れます。
注意点ですが、i2iで使う画像は生成の際に使用する指示画のようなものであり、ここで選択した画像がモデルやLoRAに学習をされると行ったことはありません。あくまで、AIが生成する際の指標となる画像ということです。
基本的に以降の生成は通常の生成と変わりないですが増えている項目として、
・Width/Heightの横に、画像サイズをフィットさせる三角定規絵文字
・CFG Scaleの下にDenoising strengthという新たな項目
が追加されています。
Denoising strengthは指示画像からどれだけ寄せるか離すかの数値です。
0~0.5は元絵に準拠する形で再生成、0.5~0.75は元絵が残った生成、0.75~1は要素が残った元絵とは違う絵の生成という具合になります。
他人の著作物を低いDenoising strengthで生成を行い、元絵とあまり差がない絵をweb上にアップロードした場合トラブルの原因になる可能性があります。仕組みを知っている人であれば基本的に悪意がなければやる人はいません。
2_4.モデルやLoRAのDLをし、使用する
モデルとは生成の際に使用する学習されたデータの塊(ベクトルの集合体)です。ファイルサイズが大きいです。
LoRAとは、AIモデル本体に影響させるDLCのような形の小規模な学習モデルです。1.5系のモデル本体が2GBとすると、100MB前後または以下のサイズが多く、作る敷居低さ、使った際の影響力の大きさで利用されることが多いです。
モデルやLoRAは無料で配布されていることが多く、好きなものをDLして使用することが出来ます。
StabilityMatrixでは、モデル配布を行っているCivitAIというサイトの専用ブラウザタブがあり、タブからDL、自動的にモデルフォルダに配置ということを行ってくれるのですが、API keyの設定をしなければいけない一手間があるので、ひとまず一般的なDLの手順を説明します。
今回は変化がわかりやすい
「8bitdiffuser 64x | a perfect pixel art model」
https://civitai.com/models/185743/8bitdiffuser-64x-or-a-perfect-pixel-art-model
を使用します。
こちらのLoRAモデルは絵をpixel art風に変化させてくれます。
通常のSD15NewVAEpruned.ckptモデルでプロンプトにpixel artと打ち込んだ場合、四角ではあるがゲーム画面を写真で撮影したような画像や、とても荒い画像が出てきたり、指定の絵が出なかったりします。
8bitdiffuser 64x LoRAを使用することで、新たにpixel artっぽい画像を出力してみましょう。
まずは上のページの青い下矢印ボタンからLoRAモデルをDLします。
エクスプローラーで
StabilityMatrix-win-x64フォルダのData→Models→Loraと移動し
Loraフォルダの中に先程DLしたモデル(バージョン違いでなければ64x64v3-02.safetensorsというような名前)を配置します。
StabilityMatrix-win-x64/Data/Models/Loraにモデルを置けたなら、webUIのページに戻ります。
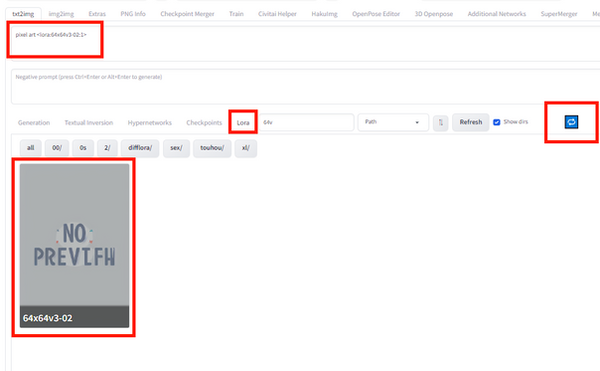
見るべきところは4点です。まず、中央のLoraタブに移動します。
フォルダに配置したばかりだと左下のグレーのモデル情報は出ていません。なので、右にある更新ボタンを押します。すると、今度こそ左下に64x64v3-02が表示されます。表示されない場合、LoRAの配置場所が間違っている場合が高いです。
64x64v3-02のグレーの画像をクリックすると、上部のプロンプトのテキストボックスに<lora:64x64v3-02:1>という文字列が自動で入力されます。これは64x64v3-02というLoRAを1の強さで使うよという指示であり、数値は-1~2まで調整することが出来ます。

一旦、プロンプトボックスにpixel artとだけ入力したSD1.5の画像が上になります。Seedは2267072124。

プロンプトボックスにpixel art <lora:64x64v3-02:1>と入力したSD1.5の画像が上になります。Seedは2267072124。
pixel art風に変化しています。これがLoRAの影響です。
LoRAはモデルにない概念をモデルに一時的に追加する形で出力することが可能になります。
ただし、LoRAモデルは小さいデータ故にモデルとかけ離れた概念は出力しづらいと言う難点があります。今のようにSD1.5モデルを使用したときよりも、イラスト特化型のモデルを使用したときのほうが精度が高いです。
StabiitMatrixをPortable設定にしている場合
モデルは
StabilityMatrix-win-x64\Data\Models\StableDiffusion
LoRAモデルは
StabilityMatrix-win-x64\Data\Models\Lora
に配置しましょう。
CivitAIなどではモデル、LoRA、vae、embedding(ネガティブ概念をまとめたもの)など様々なものが配布されています。お好みのものを探しましょう。
2_5.モデル紹介
モデル選びの指標にDLの多いイラスト系2種リアル系2種のモデルを紹介します。
prompt: 1girl,winter,looking at viewer,
Negative prompt: (worst quality, low quality:1.4)
で同設定で出力。
クリックでDLURLが表示されます。



